Introduction
This project builds a scene classifier that runs entirely on-device on iPhone. A Vision Transformer is trained on SUN397 — a scene understanding benchmark with 397 categories — and exported to CoreML for inference on Apple’s Neural Engine. The full pipeline covers attention from scratch, ViT architecture, transfer learning, Grad-CAM visualization, CoreML export, and a SwiftUI app.
Demo
Architecture — Vision Transformer
A Vision Transformer (ViT) treats an image as a sequence of patches — the same way a language model treats a sentence as a sequence of tokens.
Patch Embedding splits the image into a grid of non-overlapping patches (16×16 pixels each for ViT-B/16), then projects each patch into a 768-dimensional vector using a Conv2d layer:
self.proj = nn.Conv2d(in_channels, d_model, kernel_size=patch_size, stride=patch_size)
A 224×224 image produces 196 patches (14×14 grid). A learnable [CLS] token is prepended to the sequence, and learnable positional encodings are added so the model knows the spatial order of patches.
Self-Attention lets each patch attend to every other patch. For each patch, three vectors are computed — Query, Key, Value — and attention scores are calculated as:
Attention(Q, K, V) = softmax(QKᵀ / √d_k) · V
Multi-head attention runs this in parallel across 12 heads, each attending to different spatial relationships. After 12 transformer encoder blocks, the [CLS] token aggregates global information and is passed to a classification head.
Training
Two models were trained on a 10-class subset of SUN397:
| Model | Val Accuracy | Epochs |
|---|---|---|
| ViT-B/16 (fine-tuned, ImageNet) | higher | 15 |
| ViT from scratch | lower | 15 |
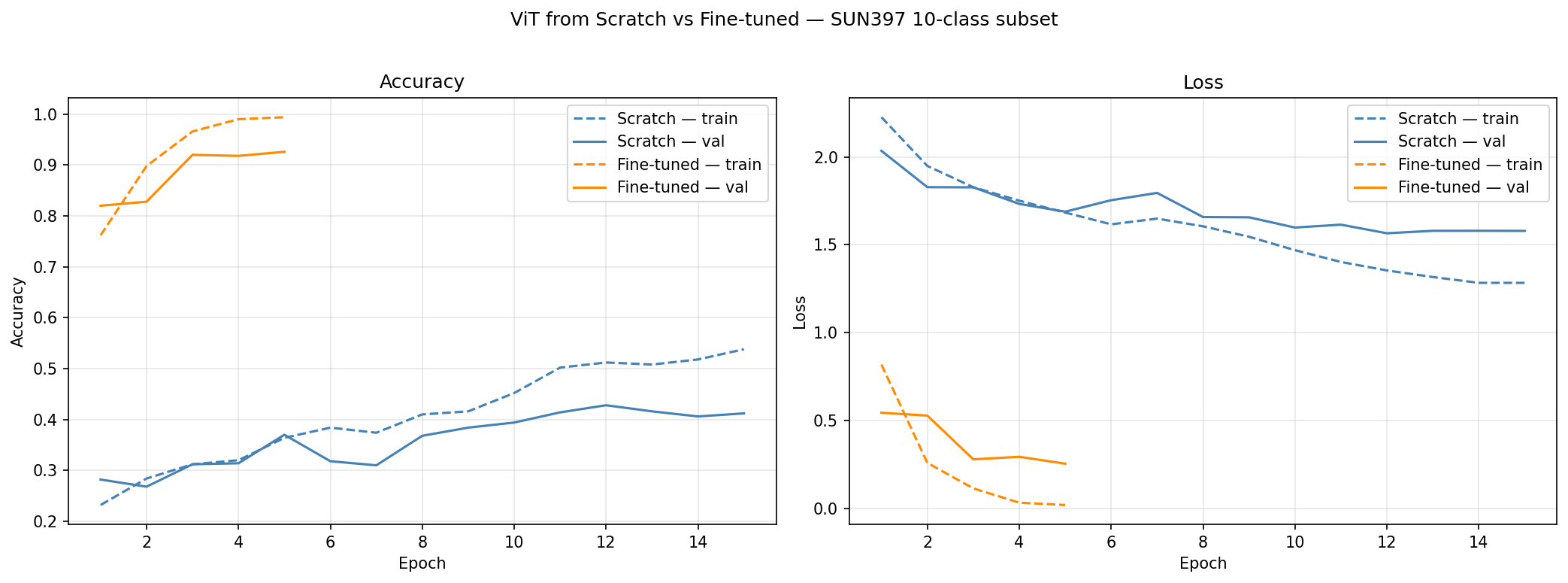
Fine-tuning the pretrained model converges faster and reaches higher accuracy — demonstrating the value of ImageNet pretraining when labeled data is limited. Training from scratch with a small dataset underfits: the transformer lacks the inductive biases of CNNs (no locality, no translation invariance), so it needs large-scale pretraining to learn useful representations.
Training setup:
- Optimizer: AdamW, lr=1e-4, weight_decay=0.01
- Scheduler: Cosine annealing over 15 epochs
- Augmentation: RandomResizedCrop, ColorJitter, HorizontalFlip
- Normalization: ImageNet mean/std
Grad-CAM Visualization
Grad-CAM (Gradient-weighted Class Activation Mapping) shows which regions of the image influenced the prediction. Gradients of the predicted class score with respect to the last transformer block’s output are used to weight the spatial feature maps, producing a heatmap over the original image.
This reveals what the model “looks at” — a beach image highlights sand and water, a kitchen highlights counters and appliances.
CoreML Export
The fine-tuned model is exported to CoreML using coremltools:
traced = torch.jit.trace(model.cpu().eval(), example_input)
mlmodel = ct.convert(
traced,
inputs=[ct.TensorType(name="image", shape=example_input.shape)],
compute_units=ct.ComputeUnit.ALL
)
mlmodel.save("vit_scene_classifier.mlpackage")
Three variants were exported and benchmarked:
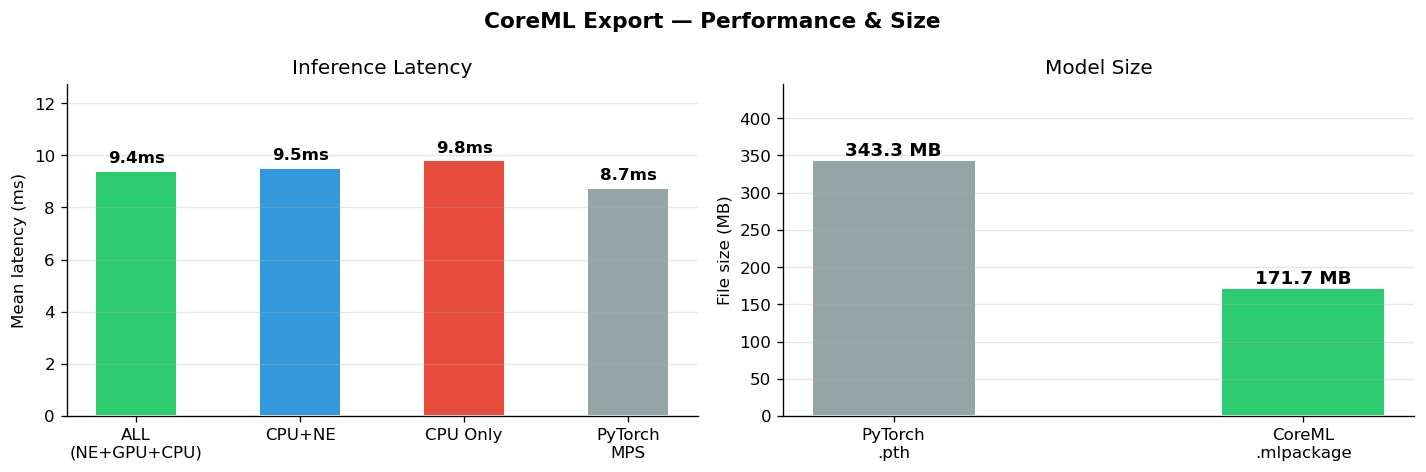
ALL routes operations across the Neural Engine, GPU, and CPU automatically — CoreML decides the optimal backend per operation.
CoreML Predictions

Green labels are correct predictions, red are misclassifications. Confidence is the softmax probability of the top class. The model does well on visually distinct scenes (beach, forest, kitchen) and struggles with ambiguous ones (living room vs bedroom, office vs restaurant).
iPhone App
The SwiftUI app loads the .mlpackage, preprocesses the selected photo, runs inference, and displays the top-3 predictions with confidence bars.
Preprocessing pipeline (equivalent to the Python transforms used during training):
// Resize + center crop to 224×224
// Convert to float, normalize with ImageNet mean/std
// Layout: [1, 3, 224, 224] CHW — same as PyTorch
Inference:
let output = try model.prediction(image: inputArray)
let logits = (0..<10).map { output.logits[[0, $0] as [NSNumber]].floatValue }
let probs = softmax(logits)
The app shows a low-confidence warning when the top prediction is below 40%, and a note that the model classifies scenes, not people or objects.
Technologies
| Technology | Used For |
|---|---|
| PyTorch + timm | Model training and pretrained ViT weights |
| HuggingFace datasets | SUN397 dataset loading |
| coremltools | CoreML export |
| SwiftUI + PhotosUI | iOS app UI |
| CoreML | On-device inference |
Challenges
SUN397 dataset unavailable via torchvision. The original Princeton download URL returns 404. The dataset was sourced from HuggingFace (tanganke/sun397) and re-uploaded to a private Hub repo for reliable access.
DataLoader multiprocessing with custom Dataset. When running notebooks via nbconvert, num_workers > 0 causes a AttributeError: Can't get attribute 'SUN397Subset' — the custom Dataset class defined in the notebook’s __main__ scope can’t be pickled by worker processes. Fix: num_workers=0.
CoreML input type mismatch. The exported model takes a raw MLMultiArray input (not an image type), so Apple’s Vision framework (VNCoreMLModel) can’t be used directly. The app preprocesses the image manually — resize, normalize, reshape to [1, 3, 224, 224] — and calls model.prediction() directly.
Insights
Pretraining matters more than architecture on small datasets. Fine-tuning ViT-B/16 on 5k images outperforms training the same architecture from scratch by a significant margin. Without pretraining, the transformer has no spatial priors and needs far more data to learn patch relationships.
Match training preprocessing exactly at inference time. The CoreML model was trained with ImageNet normalization (mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]). Skipping this step in the iOS app would produce garbage predictions. The preprocessing code in Swift mirrors the Python transforms exactly.
Confidence thresholding improves user experience. Softmax probabilities can be misleadingly high even for wrong predictions. Showing a warning when top confidence is below 40% prevents the app from presenting uncertain predictions with false confidence.
Source code on GitHub