1. Project Definition
1.1 Project Overview
This exercise aims at solving a data driven problem, using data science and machine learning skills. Here, I would like to build a convolutional neural network (CNN) based computer vision pipeline that can be used within a web or mobile app to process real-world, user-supplied images. In this project, given an image of a dog, the algorithm will identify and estimate the canine’s breed. If supplied an image of a human, the code will identify the resembling dog breed.
1.2 Problem Statement
The goal is to write an algorithm that accepts a file path to an image and first determines whether the image contains a human, dog, or neither. Then,
- if a dog is detected in the image, return the predicted breed.
- if a human is detected in the image, return the resembling dog breed.
- if neither is detected in the image, provide output that indicates an error.
The steps involved are:
- Step 0: Import Datasets
- Step 1: Detect Humans
- Step 2: Detect Dogs
- Step 3: Create a CNN to Classify Dog Breeds (from Scratch)
- Step 4: Use a CNN to Classify Dog Breeds (using Transfer Learning)
- Step 5: Create a CNN to Classify Dog Breeds (using Transfer Learning)
- Step 6: Write your Algorithm
- Step 7: Test Your Algorithm
1.3 Metrics
For this classification problem accuracy metrics is used. The accuracy metrics calculates how often predictions equal labels, that simply divides total by count.
- while building the model using a CNN from scratch, it is to be ensured that the test accuracy is greater than 1%.
- while building the model using transfer learning to create a CNN, the aim is to attain at least 60% accuracy on the test set.
2. Analysis
2.1 Data Exploration
As an initial step to solving any data-science problem, first I explore the datasets that I downloaded. Here is what I found:
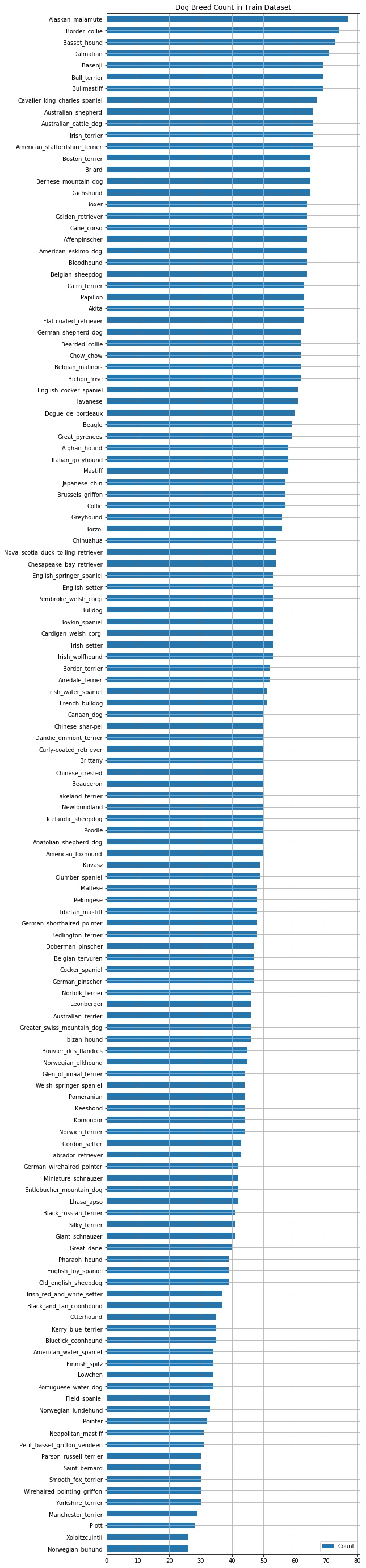
In the Dog Dataset
- There are 133 total dog categories.
- There are 8351 total dog images.
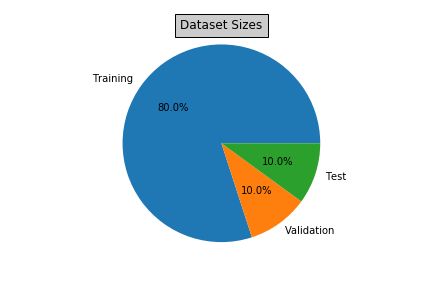
In the Human Dataset
- There are 6680 training dog images.
- There are 835 validation dog images.
- There are 836 test dog images.
Further, analysis shows that:
- There are no missing values for any of the dog categories in either of the train, validate, or test datasets for dog images.
- A similar analysis for missing values for human names seems to be irrelevant, as there could be a possibility that some of the human names are common. The human dataset does not have any other categorical data that could be further utilized.
2.2 Data Visualization
The statistics from data exploration can be visually represented as:
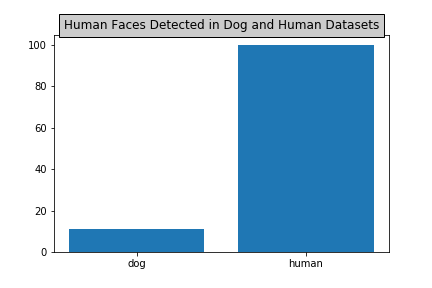
In order to be able to detect human faces in images, I use OpenCV's implementation of Haar feature-based cascade classifiers. The human face detector function detects that:
- There are 100% human faces in human_files.
- There are 11% human faces in dog_files.
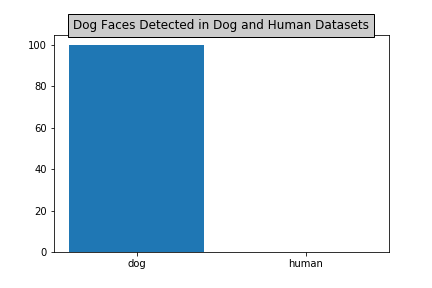
Similarly, in order to be able to detect dog faces in images, I use a pre-trained ResNet-50 model to detect dogs in images. The dog face detector function detects that:
- There are 100% dogs detected in dog_files.
- There are 0% dogs detected in human_files.
3. Methodology
3.1 Data Preprocessing
As a pre-processing step, the images are rescaled by dividing every pixel in every image by 255. This gives a value between 0 and 1 for each pixel.
Also, I created the following function, which cleans up the input strings representing the data labels and returns a data frame. This enables a convinent data analysis whenever required in the development process.

3.2 Implementation
The initial architecture of the CNN model consisted of:
CNN from scratch
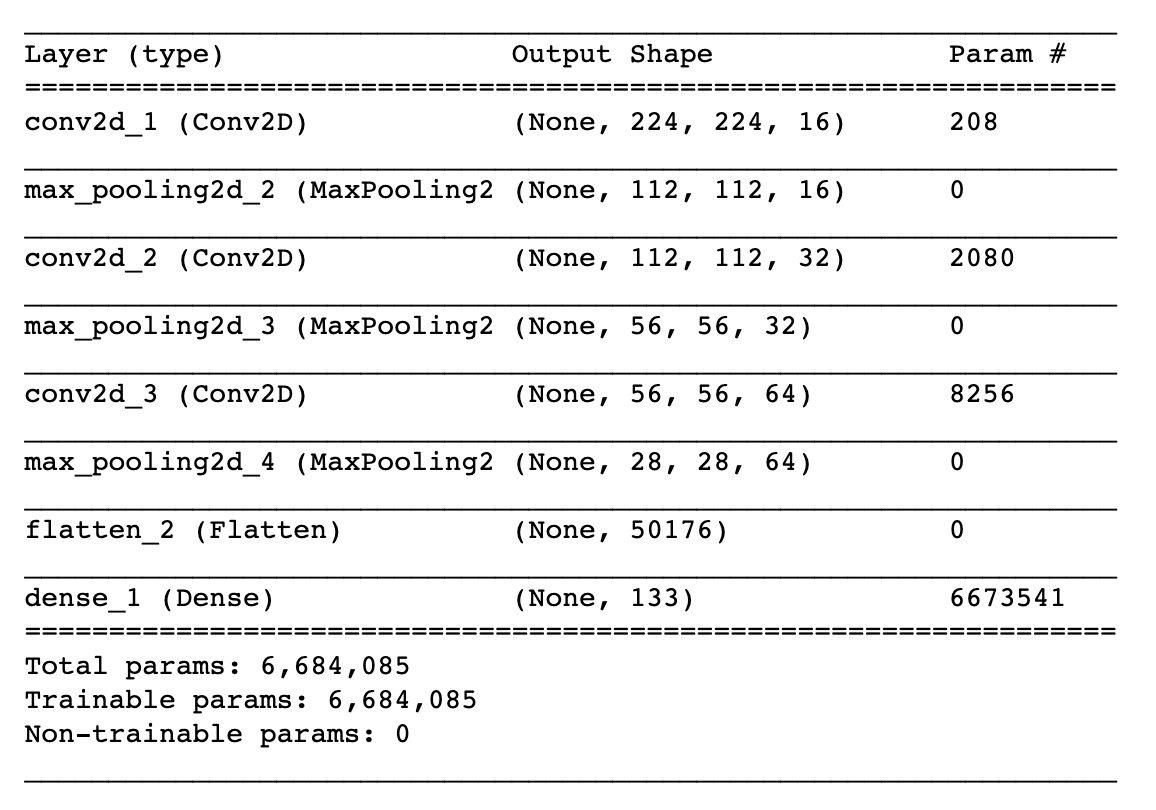
Following is an outline of steps taken for developing the CNN architecture:
1) Import several layers from Keras that will be used in the image classification task.
2) Create a CNN by first creating a Sequential model and add layers to the network by using the .add() method. In this CNN Architecture we work with colored images that are resized to height X width = 224 X 224 and has a depth = 3, corresponding to the 3 channels red, green, and blue.
3) The network begins with a sequence of three convolutional layers that reduces the height and width of the image array input from 224, 112, 56, to 28. The first layer has input shape of (224,224,3) corresponding to the input image (height, width, depth). Each convolution layer is followed by max pooling layers that increase the depth of the input image from 3, 16, 32, to 64. We also use 'relu' activation function with these layers. As a result the image array is converted to an array which is very deep and with very small spatial dimensions.
4) The resulting array that has no more spatial information left is then flattened and fed to a fully connected layer, which is a Dense layer to determine what object is contained in the image.
5) The Dense layer has a softmax activation function that returns probabilities. The number of nodes in this final layer is equal the total number of classes in the dataset, which is 133 in this case.
3.3 Refinement
There were two subsequent architectures developed in order to improve the accuracy of the CNN model that consisted of:
(i) CNN using transfer-learning with pre-trained VGG-16 model

(ii) CNN using transfer-learning with pre-trained Resnet50 model

Following is an outline of steps taken for developing the CNN architecture with the technique of transfer-learning:
1) I am extracting features of an image by taking advantage of a pre-trained CNN "Resnet50".
2) I use a global average pooling layer that reduces the height and width of the image array.
3) The final layer is Dense layer with softmax activation function and 133 output nodes equal to the number of dog categories. This layer estimates the probability of an image belonging to each of the category.
This architecture uses the technique of transfer learning, where the pre-trained network is fed to the new network with only two final layers. This immensely reduces the training time and makes it a suitable technique to solve the image classification problem.
4. Results
4.1 Model Evaluation and Validation
Test Accuracy
- For CNN model from scratch, the test accuracy is 8.1340%
- For CNN model using transfer learning with pre-trained VGG-16 model, the test accuracy is 40.3110%
- For CNN model using transfer learning with pre-trained Resnet50 model, the test accuracy is 80.3828% > 60% (desired accuracy on the test set)
4.2 Justification
Transfer Learning using pre-trained network considerably reduces the training time (from hours to minutes) and hence is a suitable technique to solve image classification problems. It results in a model with smaller validation loss and greater prediction accuracy. Based on the test-accuracy results, I am selecting the Resnet50 based model architecture for my final classifier.
5. Conclusions
5.1 Reflection
The model architecture development requires familiarity with AI related research papers and publications. I am using my prior AI-Nanodegree experience at Udacity to complete this project.
Also, resolving environment issues regarding installing opencv3, python3, keras, jupyter, mac-os was challenging and time consuming. It is highly recommended that we use virtual environments and package managers like Anaconda.
5.2 Improvement
The algorithm seems to be reasonably good in classifying images as dogs or humans or neither. However, there is a scope of improvement in the model architecture as the results from multiple runs indicate:
- Sometimes, a dog may get incorrectly classified as a human.
- Even if a dog that is classified correctly as a dog, the algorithm may not return its correct breed.
- Different pictures of the same person are suggested to resemble different dog breeds.
My GitHub Link